Building a simple columnar database.
This blog post marks the start of a (long) series of blog posts on building a Column-oriented database. I am passionate about databases and I hope I can spark a similar interest in others. For the longest time I have wanted to create a database from scratch. Since I recently switched to a 4-day work week I finally had the time to action on it. This was an amazing learning opportunity for me.
I will come back and update this post with a list of new blog posts in this series. You can also use the columnar-database-series tag to find other entries in this series.
Note that if you are following along with this series, I will not be able to explain everything. That is, I expect you have some knowledge on the following topics:
- Using databases, specifically being able to query databases with SQL
- General programming, ideally in a lower level language like C, C++, Rust. This blog will be using C++. However, where a specific C++ construct is relevant to be aware of, I will try to explain it.
- Some familiarity with database design.
- A basic understanding of computer hardware.
- A basic understanding of relational algebra.
Introduction to Columnar Databases
Row-based relational Database Management Systems (DBMS), such as Postgres & MySQL, are optimised for a transactional workload. E.g. requesting a single user from the database, looking up information about an order, etc. Often we only care about a single row, but most columns in that row will be used. E.g. in SQL:
# Fetching a user with ID ID: `bf42c8c6-3fed-4285-af85-ee5d006a7f64`.
SELECT user_id, name, address, email, is_active, category, total_spend
FROM user
WHERE user_id = "bf42c8c6-3fed-4285-af85-ee5d006a7f64"
In row-based systems, each row will be stored contiguously on-disk, often within a clustered index: all data is sorted by the index key (i.e. PRIMARY KEY of the table). The index key determines the position of the entire row on-disk.
Columnar databases, such as Snowflake & Clickhouse, are optimised for a different workload: Analytics (also referred to as Online Analytics Processing or OLAP). In analytical queries we are interested in aggregating data over the entire set (or subset) of available data. Normal queries answer questions like: what was the most-sold product in the last month? What is the average spending per user category? E.g. in SQL:
# Average spend per user category.
SELECT category, sum(total_spend) / count(*)
FROM user
GROUP BY category
In these types of analytical queries we often disregard most columns and only use a few columns (e.g. total_spend, category). If we would store the data in a row-based layout that means a lot of the data we query would be discarded. In the example query above, we would need to fetch all rows of the database, iterating over each row, and only keeping the total_spend & category columns. That is a lot of wasted resources (IO ops, memory & cpu cycles).
Using a columnar layout data will store all values within a column contiguously on-disk. To execute the above query, the DBMS would only need to fetch the total_spend & category columns from disk. None of the other columns would need to be loaded.
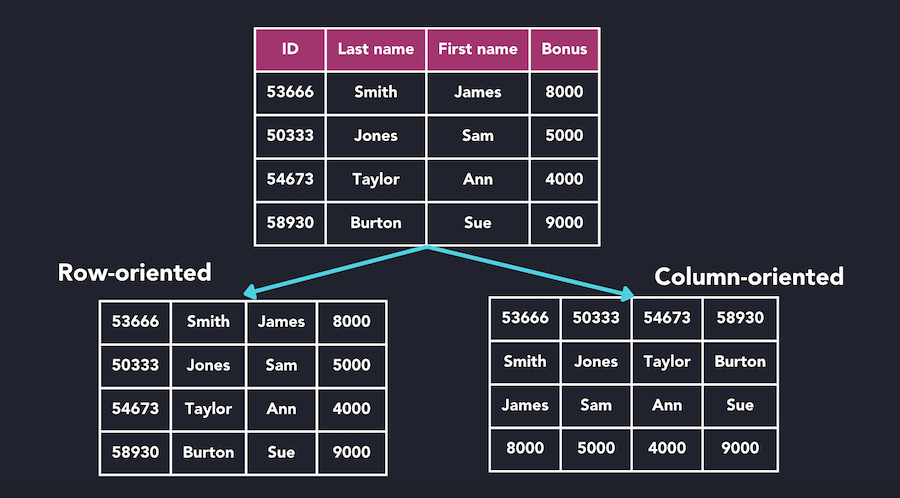 [1] Columnar vs Row based layout. Source: https://questdb.io/glossary/columnar-database/
[1] Columnar vs Row based layout. Source: https://questdb.io/glossary/columnar-database/
Innovations in Columnar Databases Research
Column-based layouts enabled several innovations in the database fields:
- Optimised storage: As mentioned in the introduction, by storing data in columns, these databases reduce the amount of irrelevant data read during query execution.
- Data Compression: All data in a column is of the same type. This means we can compress data more efficiently. We can even introduce specialised compression formats such as dictionary-encoding that require an understanding of the distribution of data.
- Vectorized Execution: Given that we process columns of similar data at the same time, we can further optimise our usage of the CPU by leveraging vectorized execution. Instead of processing row by row (or value by value), we can operate on vectors of data at a time. This has several benefits such as hiding memory stalls (all data will be loaded into the CPU cache before we operate on it) and allowing for the use of SIMD operations.
Most modern OLAP databases utilise these (and other) innovations to create the most optimised performance for Analytical workloads.
Goal: Building a columnar database
As mentioned at the start of this post, this is the start of a series about building a columnar database. However, I want to be more specific in what we are aiming to achieve. The goal will be to:
- Build a columnar database in C++.
- Designing a columnar data format (PAX style).
- Supporting vectorized execution. We will not use SIMD initially, but I will explain how we can achieve that later.
- Support basic SQL queries, including JOINs.
- Optimising queries using both heuristics (e.g. removing 1=1 and replacing it with 2) as well as cost-based & cardinality evaluation approaches
Along the way I will explain in-depth how a columnar database works. How do we parse queries and translate that into Relational Algebra (a logical plan). How do we optimise the logical plan and generate the best possible physical plan? How do we execute the physical plan. Don’t worry if not everything is clear right now.
In the end I hope to be able to load an existing dataset (such as the IMDB dataset) and perform queries on it. Then we can compare the performance of the Columnar Database we build to existing systems.